Contrastive Language Image Pre-training (CLIP)
CLIP and its Modality Gap
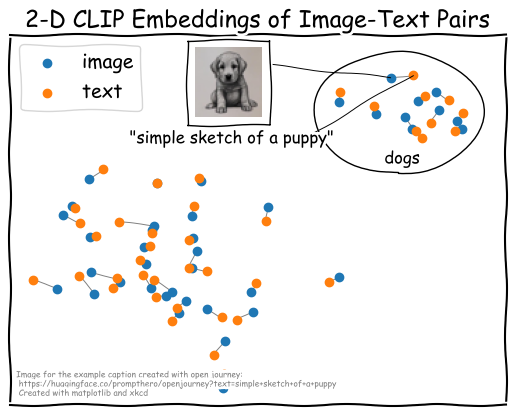
Despite the clear objective that is supposed to bring texts and images to a shared embedding space there is
a phenomenon called "Modality Gap"
The use of dimensionality reduction methods to compute a 2-dimensional view of the data clearly shows the separation between the two modalities. However, dimensionality reduction comes hand in hand with a loss of information and possible distortion of data. We propose a different way to visualize the dimensionality gap. Similarity heatmaps are a simple yet effective way of visualizing latent space embeddings that also helped us to better understand the modality gap. Using this visualization also allowed us to gain interesting insights unrelated to the modality gap, which we could not have found with the scatter plot visualization alone.
The similarity heatmap below shows the same subset of 100 image-text pairs previously shown in a scatter
plot. However, in this case, we show the cosine similarities
- top-left: in-modal similarities of the 100 image embeddings,
- bottom-right: in-modal similarities of the 100 text embeddings,
- top-right: cross-modal similarities between the 100 image embeddings and the 100 text embeddings,
- bottom-left: a transposed version of the cross-modal image-text similarities.
Now, where does this modality gap even come from?
As analyzed by Liang et al.
where
They also experimented with manually reducing the modality gap by moving the embeddings closer together along the gap vector.

However, since the modality subspaces trained by CLIP are not symmetric
Now, what do the similarity heatmap and scatter plot look like when we manually close the gap? As shown in the visualization below, the similarity matrix seems more homogeneous (i.e., in-modal similarities and cross-modal similarities are on a similar level), and points in the scatter plot are closer together. However, the scatter plot also shows that the edges between image-text pairs are still long, and the text embeddings concentrate more on the center compared to the image embeddings.
What About Other CLIP-Like Models?
As mentioned previously, the two modalities (i.e., texts and images) live on different embedding spaces, and the two embeddings vary
in structure (i.e., they are not symmetric to each other). Recently published papers propose different
versions of CLIP, where the objective function has been adjusted to regularize the trained embedding space.
We look closer into two promising approaches, namely, CyCLIP
CyCLIP
According to Goel et al.
The visualizations below already hint that the embeddings are symmetric: The in-modal similarity heatmaps of the image and text quadrants look similar, and the modalities in the image-text points in the PCA projection seem almost parallel. However, it is also clear that the modality gap is still present.
We can confirm this with a slight modification of the similarity heatmap. For this, we calculate the difference between the in-modal similarities of images and texts, which results in a matrix where values approach zero (i.e., the matrix is a blue rectangle).
When looking back to Liang et al.’s
Again, when closing the modality gap, the similarity heatmap becomes more homogenous (i.e., the in-modal similarities and cross-modal similarities are similarly strong). The image-text pairs in the scatter plot are closer, but still scattered.
Alternatively, we can use UMAP or tSNE projection to better utilize the neighborhoods of similar embeddings instead of linearly determining the axes with the highest variance, as done in PCA. In the case of CyCLIP (scatter plot on the right hand), the use of a neighborhood-based dimensionality reduction technique results in shorter edges and better clustering of similar embeddings. For CLIP (scatter plot on the left hand), edges remain long, and similar images and texts are not clustered together. See the Appendix for examples with 5000 samples.
Let us summarize how the loss changes for CLIP and CyCLIP when moving the embeddings together along the modality gap vector. For that, we again use the entire MSCOCO validation dataset of 5000 samples.
| Model | Original Distance | Original Loss | Closed Distance | Closed Loss | Loss Difference |
|---|---|---|---|---|---|
| CLIP | 0.818611 | 0.355370 | 0.035077 | 1.124780 | 0.769410 |
| CyCLIP | 0.873026 | 0.763433 | 0.001218 | 0.848867 | 0.085434 |
The numbers confirm that CyCLIP's loss changes far less than CLIP's loss when manually closing the gap – it neither gets better nor significantly worse. However, the question arises:
Why Do We Even Want to Close the Modality Gap, if We Do Not Gain Performance?
From a performance optimization point of view, this is a valid question. What's the point of interfering in
a well-performing system? On the other hand, the alignment of embedding spaces can become important for
other downstream tasks. For example, using image and text embeddings interchangeably, as done in
language-guided image generation, relies on the fact that image and text embeddings are aligned with each
other and live in the same space. Another aspect is that an aligned embedding space is closer to how humans
expect multi-modal models to see the data. Furthermore, closing the modality gap allows us to actually
visualize texts and images in the same space, and develop interactive exploration tools that help to
understand multi-modal data (e.g., analyzing pairs of human written captions and machine-generated images to
find insights about text-to-image generation models like StableDiffusion
These example use cases of why closing the modality gap might be helpful should give you an incentive about why the pure "performance optimization" point of view is not the only one. In fact, if we can close the modality gap without significantly losing performance, we have a win-win situation!
CLOOB
In the previous section, we established a way to manually close the modality gap of CyCLIP embeddings. However, wouldn’t it be better to already close the gap during training and not rely on post-hoc manipulations? While we did not experiment with further modifying (Cy)CLIP’s objective to close the gap during training, we stumbled upon a different learning approach that naturally closes the gap.
Contrastive Leave One Out Boost (short: CLOOB)
However, we also observe something else: These modifications seem to aid the closure of the modality gap!
We believe that CLOOB’s ability to close the gap during training mainly stems from the cross-modality retrieval
applied before calculating the InfoLOOB loss. In this step, the batch of image embeddings
and text embeddings is used as an associative memory to create a weighted average of embeddings for the
current instance. Since this is done for each combination of embedding and associative memory (i.e., each
image and each text embedding is associated with the entire batch of image embeddings AND the entire batch
of text embeddings), a stronger correlation between the image/text instances to their own
modality and the opposite modality is established.
Other influencing factors on closing the modality gap could be the use of InfoLOOB, or the use of modern Hopfield networks
that generally have a denoising effect
Summary of Modality Gap Analysis
The following visualizations give an overview of the similarity heatmap for CLIP and CyCLIP before (left)
and after (right) manually removing the modality gap, as well as the similarity heatmap for CLOOB with the
official checkpoints from the paper and a CLOOB version that was trained on the LAION 400M dataset and used
a ViT instead of a CNN to encode images
The previous sections taught us about the modality gap, where it comes from, and ways to close it. We also gave reasons for why closing the gap might be beneficial and now demonstrate how closing the modality gap can help with analyzing multi-modal data. We also introduced a handy new way of visualizing latent space embeddings and utilize this again in the following analyses. Finally, we also want to mention that there is a way to visually close the modality gap (i.e., without actually closing the gap in the embedding space), as described in the Appendix.
Converting the Technique into a Tool
Using the previously introduced techniques, we implemented an interactive prototype called “Amumo” (Analyze Multi-Modal Models). Users can switch between models, explore the similarity heatmap and scatter plot visualizations, manually close the modality gap, and try various projection methods.
Identifying Data Subsets
We can look into semantic subsets of data by filtering instances based on their captions. The following example shows the visualizations for the subset that contains the substring "dog". We notice that some lines in the similarity matrix have a darker color. When hovering over those darker lines, we can see that most of these instances correspond to images and texts about "hot dogs" or other images that do not show a dog or where a dog is in an uncommon setting. To make this even more obvious, we can use the "Cluster matrix by similarity" function that reorders the similarity heatmap such that similar lines are grouped together. One cluster that stands out in all three CLIP-like models is the "hot dog" cluster. However, we can also see clusters for "dog and frisbee", "dog and bed", or "dog and car".
Analyze DiffusionDB Dataset
We would like to see what the models’ latent-space embeddings look like for a dataset that is not (entirely)
procured by humans. To this end, we use DiffusionDB
With the default settings, we randomly explore the dataset and get a feeling for the data contained in this subset. We can investigate instances that are outliers in the similarity heatmap by hovering rows or cells that have particularly large or low similarity values. For example, there are some particularly bright cells scattered in the image in-modal similarity heatmap. Upon hovering, we see that all of these images are blurry. We know that DiffusionDB added blur filters for images that were detected to show inappropriate content. Interestingly, CLIP seems to create similar latent embeddings for blurry items, causing them to show high similarity in the similarity heatmap.
For further analyses, we choose "Cluster matrix by similarity" to order the matrix in a way that groups similar rows in the heatmap and investigate the clusters that are emerging. We can see a cluster for "impressionism and crystal" that seems to have homomorphic similarities over all images (i.e., there is a distinct purple line along all images of this cluster). Upon further investigation, we see that the captions in this cluster are mostly vague texts or single words (e.g., "crystal", "impressionism") that can apply to a lot of images. The same cluster becomes apparent in the text in-modal similarity heatmap, where all captions within the cluster seem to have high similarity.
Let’s close the modality gap to investigate clusters in a 2-dimensional scatter plot. We can either do this by switching to the CLOOB model or using CyCLIP in combination with the "Close modality gap" option. We see that the embeddings are aligned and can use the interactive scatter plot to investigate clusters. For example, we can try to find the cluster of blurry images, or we can try to find the cluster with instances of "impressionism". Of course, this would be much more fun on a larger scale :)
Augmentation Analyses
As previously demonstrated, we can identify patterns in datasets and subsets of datasets using the similarity heatmap visualizations. Now, we would also like to see if we can use the same techniques to find patterns in augmentations of a single data point. For example, we take a single image, generate rotated versions of this image, and use this augmented dataset to compute CLIP embeddings and similarities. The results of this experiment for the three CLIP-like models are shown in the visualization below (note that we again show two variants of the CLOOB model). To generate this dataset, we gradually rotate a selected image by 360 degrees over the course of 100 steps. Each step results in a “new” image and a new data point. Note that we only augment the image, but not the text, which results in a completely homogeneous similarity in the in-modal text quadrant of the heatmap and homogenous stripes along the text dimension in the cross-modal quadrants of the heatmap.
When looking at the in-modal image similarity quadrant of the heatmap for each model using augmentations of
the first image, we can see an interesting pattern emerge. In addition to the bright yellow diagonal axis
that corresponds to the similarities of images to themselves, there is also the perpendicular off-diagonal
axis of the matrix sticking out. When hovering along the off-diagonal, we see that the two images along this
axis are actually mirrored versions of each other. It seems like all models are invariant to the horizontal
flip transformation for this image. We can also see a checkerboard-like pattern emerge for some images
emerging in all models except for the CLOOB_LAION400M. When looking into the darker areas of this heatmap in
more detail, we can see that the pattern occurs around multiples of 90-degree rotations. The fact that this
pattern occurs mainly for the three models that use a CNN-based image encoder
When looking at the overall distribution of similarity values, we also notice that the ViT-based CLOOB model seems to have more patches of low-similarity values compared to its CNN-based counterparts. This might indicate that ViT’s overall robustness to rotation transformations is lower. In further investigations, we might want to directly compare two versions of CLIP: the current version with the CNN-based image encoder and a version with a ViT-based image encoder, and study the phenomenon on a larger dataset.
Use the interactions to explore the heatmaps for different images yourself.
In a second experiment, we analyze the heatmaps for an image to which we add an increasingly higher noise level. When looking at the heatmaps for the first image, it seems like there is a certain level of noise for each model, after which the model cannot seem to recognize the content of the image anymore. All images with a higher level of noise than this threshold seem to look (almost) the same (as indicated by a bright yellow rectangle at the lower-right corner of the in-modal image similarity quadrant).
Similarly, for blurry images, we see that at a certain point of blurriness, all images look the same to the models, and they cannot map images and texts together. You can use the dropdown menu to explore the effects of various augmentations.
Conclusion
Throughout this article, we investigated latent embeddings of CLIP-like models. Using scatter plots and similarity heatmaps, we visualized and analyzed the modality gap that naturally occurs for CLIP embeddings. Closing this gap without losing significant performance can be important for downstream tasks like image generation, visual analytics, or human understanding. We showed how to close the gap using CyCLIP in combination with a post-processing method that aligns the embedding spaces and investigated another model (CLOOB) that is able to align the spaces during training. Finally, we introduced Amumo, an interactive visual prototype that allows users to explore embeddings from bi-modal contrastive learning models to help with understanding of their latent space embeddings. We used Amumo to analyze various (sub-)sets and augmentations of data. We believe that Amumo, and the similarity heatmap in particular, are useful tools to create intuition about bi-modal latent space embeddings. It allows for comparison of bi-modal models (e.g., their robustness to transformations) and can help to formulate hypotheses or ideas about such models. However, we want to stress that the analysis is based on a small subset of data points, and insights must still be verified on a larger scale.





